
This meme summarizes perfectly how intense these past two weeks since my last update has been. So much progress, so many things being cooked. And as always, the readers of these letters are the ones getting the news first-hand as they are being cooked. I am starting these words without a clear picture of how (and if) I am going to be able to cover all that I want to share today. Even more, I have the bad (but appreciated by many) habit of not using LLMs to write any of my pieces, so I don’t know what is going to get out of this. Expect typos, non native English and messy writing style!

Baselight AI v1
Baselight AI v1 is not only a reality, but I am already seeing myself using it every day (as you can see in the screenshot below and here)! Like two-weeks ago, it is still in private alpha, but we are planning to release it to all Baselight users already in the coming days, so stay tuned!
Even before releasing it to all users, we are already squashing bug reports and getting new features every day. Here are a few of the highlights:
- Charts in chat: Baselight AI knows how to create charts in-chat. It can now visualize query results directly and render both bar and line charts based on the data context. What makes this powerful is that charts can be controlled entirely through natural language – the assistant understands instructions like “show this as a line chart,” “compare by month,” or “use revenue instead of sales.” It’s possible to change axes, adjust what data is displayed, and refine the visualization step by step without leaving the conversation.
- UX enhancements: We’ve added the possibility for creating queries directly from chat, private dataset access. You can now upload your own datasets and cross-reference them with public datasets, enabling seamless interaction with private and public datasets.
- Search improvements: This is not a change exclusive for the Baselight AI but that shows a clear improvement on the UX of the platform and the performance of LLMs interacting with Baselight and Baselight AI itself. We’ve upgraded to the latest version of Typesense for faster and more reliable search performance. We are already investigating an embedding-based indexing to allow richer, more contextual discovery of tables and datasets.
- Storage optimisations: Finally, the increase in the number of queries that we are receiving through the MCP interactions and Baselight AI was bloating the storage capacity of our machines. With this in mind, we’ve started migrating from local storage to S3 for better scalability and reliability. There are more optimisations in the pipeline being implemented that should improve the performance across the board, but let’s leave that for a future update.
- Prompting and context management improvements: This is a bit of the secret sauce that I am keeping to myself, but those of you already using BaselightAI as alpha users may have seen a more “aligned” and “smarter” assistant since a few days ago. Who said AI alignment wasn’t fun? 🙂
The TL;DR is that all of these changes should have improved the experience of using BaselightAI and its ability to answer your questions (even with visuals) more efficiently!
A new landing page and a product demo
Baselight is growing so fast as a product: from the data catalog, to the Baselight AI, to dashboards, to the MCP integration, etc. that we decided to record a new product demo to walk everyone through what Baselight is, and what you can do with it.
And in line with this, we are working on a complete re-work of the landing page that better reflects our product offering, the long-term vision for Baselight, and how we are solving a fundamental problem for AI and humans.
<This was a placeholder for a screenshot of the beautiful design that we are working on, but I didn’t want to ruin the surprise, so I restrained myself. Stay tuned!>
A few datasets that I was really missing
And I couldn’t close this letter without a brief mention of these past weeks’ data updates. You know you can follow the progress of how the amount of datasets is growing in the platform from this dashboard:
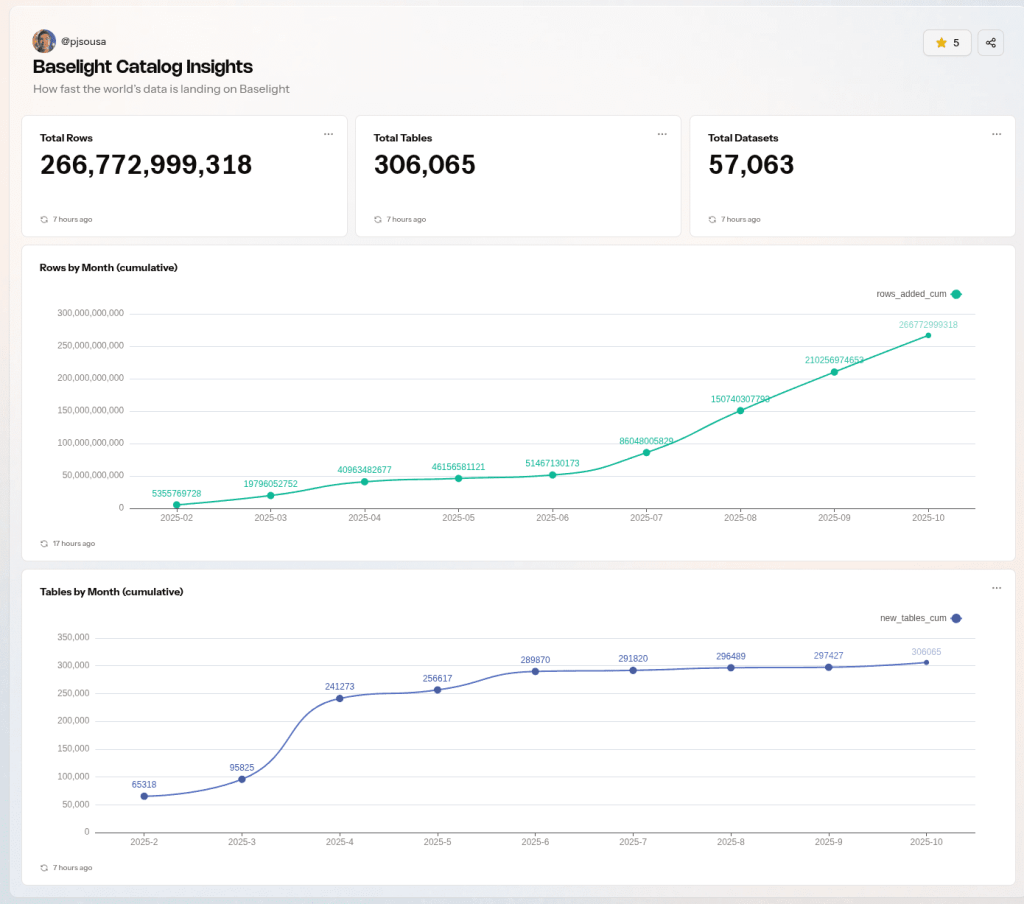
But this week I am personally even more pumped because we’ve on-boarded a few datasets that I was really missing for my own analyses. Mainly:
- International Monetary Fund (IMF) data
- SEC Filings data
- Gapminder
- And a lot of improvements for decoded data in the Ethereum blockchain and to our flagships sports datasets to make them more amenable to be queried and analysed.
There are a few more cool ones coming to the platform, but if you have any requests or any datasets that you feel you were missing in your last few analyses please let me know!
This has been a crazy past two weeks, and I expect the coming ones to be even more exciting. I wanted to keep this one dense and brief. I hope I did a decent job. Worst case scenario we can probably feed this to an LLM and ask it to re-write in a more readable form. Looking forward to catching up in two weeks!
Alfonso de la Rocha – CTO
https://x.com/adlrocha